随着信息化时代的来临,大数据越来越被重视,数据采集的挑战变的尤为突出。许多大型企业和****在信息化过程中结合自身业务搭建起了各种各样的软件系统,其中积累了大量的行业和**,他们急需将这些数据汇聚起来,形成自己的大数据平台,做数据挖掘和分析,精细地服务他们的客户。当前数据采集的挑战如下:1、...
数据采集基本参数
- 品牌
- 飞莱栖信息科技,光程生产执行系统
- 型号
- 数据采集
数据采集企业商机
对事件里的属性内容进行二次加工,甚至是修正。一方面保证数据采集的准确性,另一方面保证数据的完整性。因为神策客户大多数采用私有化部署,神策难以统计用户数据丢失率,但是在业界普遍标准是“App的数据丢失率在1%左右,H5和Web的数据丢失率在5%左右”,之所以有5倍差异,是因为H5的本地缓存是有限的,数据上传失败就意味着丢失;另外,大多情况下H5在App中以单页面形式存在,H5发送网络请求之后,如果用户退出页面,其网络请求随之被取消,没有办法实现完全同步,这种情况下数据“打通”便朝着更高要求、高标准迈进——如何“打通”App与H5降低数据丢失率?App采集的事件并非实时同步,因为App内事件多、频率高,每次采集后立即同步会给服务器带来很大的压力,所以一般情况下,App内会增加本地缓存,所有采集到的事件先存入本地缓存,达到一定条件后再进行同步。也就是说,根据缓存制定相应的数据同步策略。如果按照以上方案,将H5的事件传给App进行二次加工,进入App端的本地缓存,走App端事件同步策略,就能**降低H5事件丢失的概率。这是我们在App与H5打通的第二版中着重处理的内容,在该解决方案中,不管是用户标识、数据准确性,还是数据完整性,都能得到解决。数据采集可以帮助企业分析市场趋势和竞争对手的行为,为制定战略决策提供可靠的依据。扬州数控数据采集怎么收费
②计算变量:计算变量的目的是调用决策引擎;③调用决策引擎:部署有催收策略;④确定催收策略:将变量传给决策引擎后,决策引擎会返回确定的催收策略。产生“是否催收、自己催or外包、如何催、分配给哪位催收员、什么时候打电话、用哪个沟通模板”等类型风险决策;⑤分配催收任务:根据案件催收难度分配给不同催收员;⑥记录催收结果:将催收结果进行归类,如:失联、无人接听、占线、承诺还款等。四、征信平台系统策略和模型的基础是数据,数据分为内部数据和外部数据,调用外部数据就是由征信平台系统进行。**功能模块:调用、解析、征信数据库①调用:将客户参数调用传给外部数据源相关机构,如:人行征信报告、百行征信报告、NCIIC等,相关**以封装加密形式返回,返回的数据一般包括客户的个人工作单位、婚姻、学历、***开卡、还款情况等;②解析:解析有两层功能含义,一是***返回的数据,二是将文本串信息进行标准化,使数据变成能够在标准数据库中存储的形式;③征信数据库:储存解析好的征信数据。五、决策引擎系统它是一种基于特地业务场景开发的定制引擎,中间充当一个变量计算和决策判断的功能,以“处理变量然后输出变量”的方式将风控决策落地。池州生产数据采集哪个好数据有测试数据,有内容数据,有历史数据,通过对数据的采集,能够让抽象的数据具体化。
作者:陆兴海彭华盛编著来源:大数据DT(ID:hzdashuju)人们对新事物的认知过程总是螺旋式迭代演进的,对于智能运维也是如此,智能运维是运维发展的方向,而且是一个长期的过程—从经验主义到数据驱动,再回归到业务驱动的过程。从2016年对于Gartner的概念的理解,到之后每一年不断的探索与实践,到2020年,在笔者参加的智能运维国家标准编写组会议上,行业内达成了高度的、更加面向现实的共识:以数据为基础、以场景为导向、以算法为支撑,如图2-1所示。▲图2-1行业对智能运维发展演进的理解智能运维一定来源于非常好的数据基础,同时,如果没有明确的业务场景,或者需求,或者功能方面的落脚点,所谓的智能化就是为了AI而AI,也没有意义。工程化算法是要拟合数据的,根据数据和场景需求才能选择或研发合适的算法。只有具备上述三个条件,才能真正形成一个工程化落地的智能运维,如图2-2所示。▲图2-2“三架马车”工程化落地的智能运维需要着重提及的是,以往很多用户忽略了作为智能业务运维“基石”的运维数据的重要性。为切实落地企业的智能业务运维规划,一方面要强调运维数据的基础作用,另一方面要形成运维数据治理与应用的全局体系。
组织的管理者应在适当时,通过对以下问题的分析,评估其有效性:[6]①提供决策的信息是否充分、可信,是否存在因信息不足、失准、滞后而导致决策失误的问题;[6]②信息对持续改进质量管理体系、过程、产品所发挥的作用是否与期望值一致,是否在产品实现过程中有效运用数据分析;[6]③收集数据的目的是否明确,收集的数据是否真实和充分,信息渠道是否畅通;[6]④数据分析方法是否合理,是否将风险控制在可接受的范围;[6]⑤数据分析所需资源是否得到保障。[6]数据分析案例编辑1、沃尔玛经典营销案例:啤酒与尿布“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析**时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。[7]在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。数据采集的结果可以通过数据分析和可视化工具来展示和解释,以帮助人们更好地理解数据。
iOS一般使用IDFA或IDFV,H5一般使用Cookie),进而就会导致一个用户使用了我们的产品,结果产生了两个匿名用户的情况。如果App与H5打通,就可以将两个匿名ID做归一化处理(以App端匿名ID为准)。那如何打通呢?在实现App与H5打通的过程中,神策数据经历了三个阶段,相对应地设计三个方案以应对不同时期的需求。方案一:设想一个场景,你的App中嵌入了一个H5,如果用户启动App但没有进行注册或登录,这个时候该如何标识用户?我们可能会用匿名ID或者设备ID进行标记,但是H5和App的匿名ID生成规则是不一样的,H5常用的是Cookie;Android常用的是AndroidID,或者**近比较流行的OAID,或者UUID;在iOS系统中,我们常用的是IDFA,当IDFA被限制后,可以用IDFV。因此,不管是Android还是iOS,在跟H5进行混合的时候,用户在产品上没有注册或的登录的时候,会产生两个匿名ID,就相当于有两个匿名用户存在,这明显与实际不符。所以我们**初做数据打通时就面临着户标识的问题。在启动内嵌入H5的时候,主动把App端生成的匿名ID传给H5,这样H5产生的所有事件都可以用App传来的匿名ID进行标识,完成用户标识统一,这是2016年神策在处理App与H5打通的***版解决方案。数据采集可以帮助企业发现潜在的商机和市场机会,提高竞争力。衢州哪些数据采集管理系统
数据采集可以帮助企业建立完善的数据分析体系,为企业发展提供有力的支持。扬州数控数据采集怎么收费
是指H5集成JavaScript数据采集SDK后,H5触发的事件不直接同步给服务端,而是先发给App端的数据采集SDK,经App端数据采集SDK二次加工处理后入本地缓存再进行同步。App为什么要与H5打通呢?主要是从以下几个角度考虑。1.数据丢失率在业界,App端采集数据的丢失率一般在1%左右,而H5采集数据的丢失率一般在5%左右(主要是因为缓存、网络或切换页面等原因)。因此,如果App与H5打通,H5触发的所有事件都可以先发给App端数据采集SDK,经过App端二次加工处理后并入本地缓存,在符合特定策略之后再进行同步数据,即可把数据丢失率由5%降到1%左右。2.数据准确性众所周知,H5无法直接获取设备相关的信息,只能通过解析UserAgent值获取到有限的信息,而解析UserAgent值,至少会面临如下两个问题:(1)有些信息通过解析UserAgent值根本获取不到,比如应用程序的版本号等;(2)有些信息通过解析UserAgent值可以获取到,但内容可能不正确。如果App与H5打通,由App端数据采集SDK补充这些信息,即可确保事件信息的准确性和完整性。3.用户标识如果用户在App端注册或登录之前使用我们的产品,我们一般都是使用匿名ID来标识用户。而App与H5标识匿名用户的规则不一样。扬州数控数据采集怎么收费
与数据采集相关的文章
镇江定做数据采集哪个好
- 扬州定制数据采集供应商 2024-05-08
- 无锡光学数据采集系统 2024-05-08
- 扬州靠谱的数据采集方案 2024-05-07
- 宿迁企业数据采集软件 2024-05-07
- 宿迁生产数据采集价格 2024-05-07
- 温州企业数据采集软件 2024-05-07
- 宿迁靠谱的数据采集单价 2024-05-07
- 宁波本地数据采集怎么收费 2024-05-07
- 衢州信息化数据采集多少钱 2024-05-07
- 绍兴定制数据采集哪个好 2024-05-07
- 淮安如何数据采集订制价格 2024-05-07
- 宿迁数据采集管理系统 2024-05-06
与数据采集相关的产品

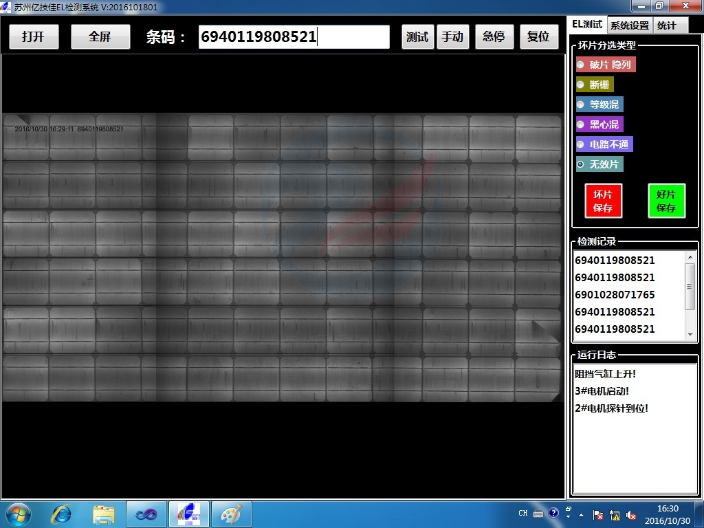
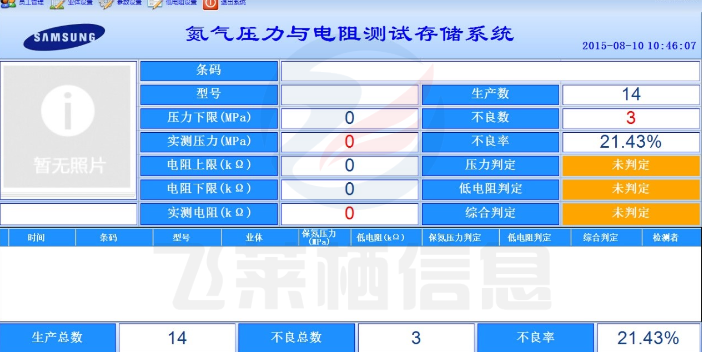
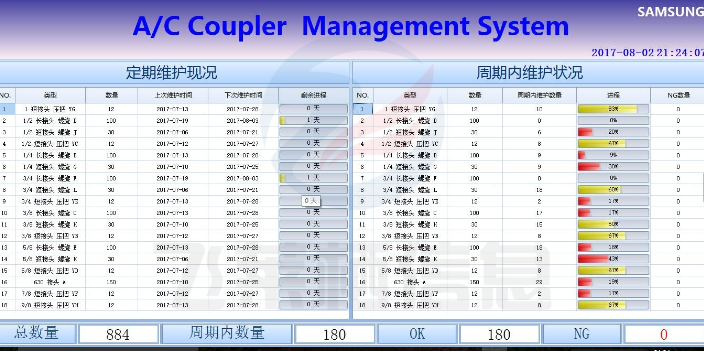
与数据采集相关的新闻
-
嘉兴数控数据采集价格 2024-05-06 13:05:17而且还从业务和技术两个角度讲解了传统的金融风控体系如何与智能风控方法实现双剑合璧。03智能风控平台:架构、设计与实现作者:郑江推荐语本书讲解了如何基于不同业务场景的智能风控方法来构建一个从数据到计算再到决策的通用智能风控平台,该平台既能应用于业务的全流程,又能承载互联网业务中的大部分风险控制...
-
盐城数据数据采集费用 2024-05-06 05:06:25不同应用领域的大数据其特点、数据量、用户群体均不相同。不同领域根据数据源的物理性质及数据分析的目标采取不同的数据采集方法。通过了解数据采集的三大要点,选择***、准确、高效的数据合作伙伴至关重要。二、数据采集方式有哪些?数据感知可分为“硬感知”和“软感知”,面向不同场景,即数据采集技术可以分...
-
金华质量数据采集参考价 2024-05-06 11:05:22因此对数据的实时处理有着较高的要求。如果将数据上传到云端,云端分析后再绕一圈回来,指导下一步动作,一来一回产生的时延,很多时候将变得不可接受。上述业务场景将在靠近数据源头的现场对数据进行即时处理,实时分析,提取特征量,然后基于分析的结果进行本地决策,指导下一步动作,同时将分析结果上传到云端,...
-
泰州数据数据采集系统 2024-05-06 15:05:02审批的过程中会涉及到人工审批,人工审批系统内部运作也主要分为三大模块:**功能模块:收集数据、展示数据、执行人工决策①收集数据:收集申请表信息、影像资料、上游审批记录等;②展示数据:收集完数据后,通过人工界面展示给信审信人员看;③执行人工决策:信审信人员通过展示数据作出决策。另外,基于业务逻...
与数据采集相关的问题
新闻资讯
产品推荐
-
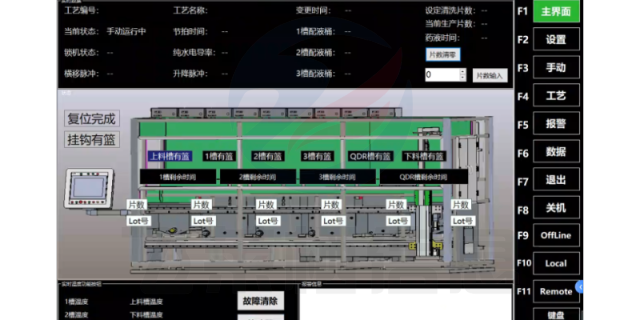
江苏维护上位机程序设计
2024-06-24 -
上位机程序设计
2024-06-24 -
上海农业上位机管理系统
2024-06-24 -

上位机软件系统软件开发
2024-06-24 -
江苏自动化上位机SECS/GEM
2024-06-23 -

广东上位机PLC采集公司
2024-06-23 -
江苏农业上位机RS232通讯
2024-06-23 -
工业上位机深度学习
2024-06-23 -
浙江农业上位机MES对接
2024-06-23